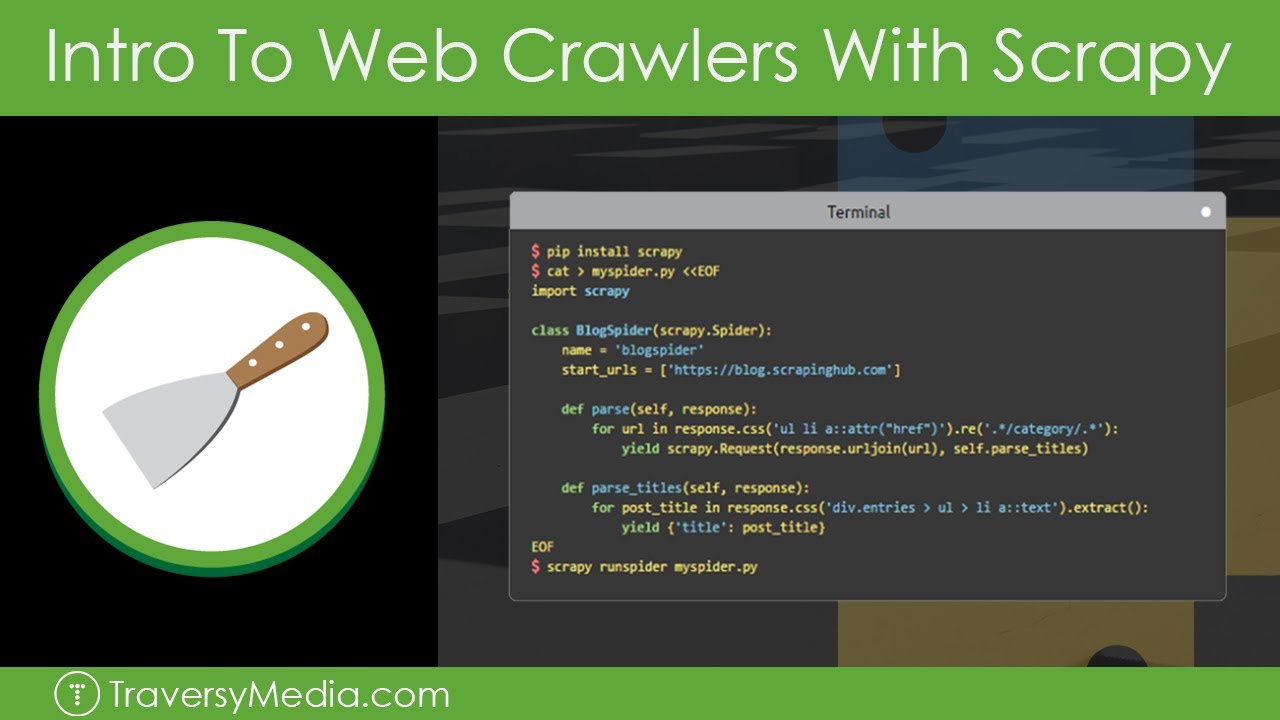
Scrapy is an open-source web crawling and scraping framework developed in 2008 by Pablo Hoffman. Based in San Francisco, California, it provides developers with a comprehensive toolkit for extracting data from websites and boasts efficient, flexible, and scalable solutions. As a leading framework in its field, Scrapy supports a wide range of applications, from simple data mining to complex web crawling projects, and is supported by a robust community and ongoing updates.
What Is Scrapy Good For?
Scrapy is particularly useful for automating the process of extracting structured data from web pages. This includes data mining, information processing, and historical archiving applications. It excels in scenarios that require efficient web scraping and crawling capabilities, offering features such as spider contracts, feed exports, and built-in support for multiple output formats. Additionally, Scrapy is beneficial for projects that require advanced web scraping features such as cookie handling, session handling, and middleware integration.
Who Should Use Scrapy?
Scrapy is designed for a wide range of users, including developers, data scientists, and organizations that need efficient data extraction and web crawling capabilities. Its versatility makes it suitable for hobbyists interested in small-scale projects, as well as enterprises that need robust, scalable solutions for large-scale data extraction tasks. The framework’s flexible pricing model, from a free open source version to higher tier plans on the Scrapy Cloud, ensures accessibility for individual developers, startups, and large enterprises alike.







")
")
")


{kind=link}
{kind=link}
{kind=link}
{kind=link}